
Connect with us
Corporate Video

Optimizing LLM-Based Chatbots: How to Reduce Latency & Improve Response Accuracy
-min.png)
AI chatbots have become a standard in customer service, automation, and business interactions. Whether it’s answering support queries, booking appointments, or providing product recommendations, chatbots are handling millions of conversations every day. But when chatbots lag or give incorrect responses, they quickly frustrate users.
For developers, making chatbots fast and reliable isn’t always simple. Large Language Models (LLMs) come with heavy computational costs, slowing down responses. Some chatbots generate misleading answers, making it hard to trust their output. And balancing performance with infrastructure costs is another challenge—run a large model on a powerful GPU, and the costs can shoot up quickly.
- Reducing inference latency with model compression, quantization, and efficient hardware choices.
- Improving response accuracy using fine-tuning, prompt engineering, and retrieval-based methods.
- Choosing the right infrastructure for chatbot deployment—whether API-based, self-hosted, or hybrid approaches.
If you’re building or optimizing an AI chatbot, these techniques will help you make smarter decisions for better performance.
Want a quick guide to chatbot optimization? Download our free AI Chatbot Optimization Checklist to get started!
Factors Affecting Latency in LLM-Based Chatbots
Speed matters in chatbots. If a response takes too long, users lose patience, and the experience feels sluggish. Large Language Models (LLMs) are powerful, but they require heavy computation, making fast responses a challenge. Understanding why chatbots slow down is the first step in optimizing them.
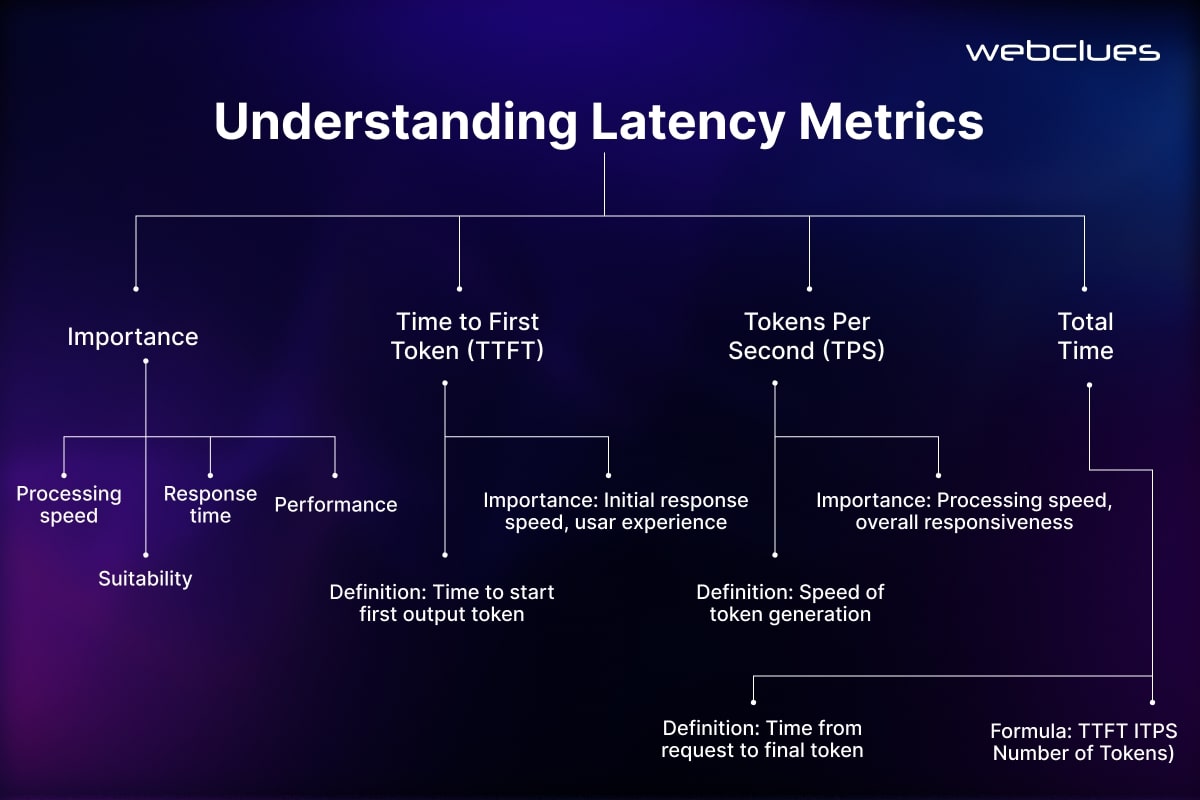
Here’s a look at the key factors that affect latency and what can be done to speed things up.
Model Complexity & Size
Bigger models mean better accuracy, but they also come with higher inference costs. A model like GPT-4 can generate detailed, well-structured responses, but it takes several seconds to process long inputs. On the other hand, lighter models like Mistral 7B are much faster while still maintaining decent accuracy.
The trade-off is simple: the larger the model, the slower the response—unless optimized properly.
| Model | Parameters | Avg. Inference Time (per 1000 Tokens) | Best Use Case |
| GPT-4 | 1.76T | ~5s | High-accuracy responses |
| Llama 2-13B | 13B | ~1.2s | Balanced performance |
| Mistral 7B | 7B | ~0.8s | Low-latency real-time chatbots |
If your chatbot needs quick responses and can work with slightly lower accuracy, models like Mistral 7B or Llama 2-13B are good choices. For high-accuracy applications, you may have to optimize GPT-4 or fine-tune a smaller model to perform well for your specific use case.
Computational Bottlenecks & Hardware Constraints
Even with the right model size, inference speed depends on how efficiently the chatbot processes requests.
Why Chatbots Feel Slow: The Autoregressive Bottleneck
Most LLMs are autoregressive, meaning they generate text one token at a time. Unlike traditional machine learning models, they can’t predict multiple tokens at once, which slows down response times.
Ways to Speed Up Execution:
- Multi-threading & parallel inference – Running multiple predictions at once reduces waiting time.
- Batch processing – Instead of handling one user request at a time, chatbots can group multiple queries to speed things up.
- Model sharding & distributed inference – Splitting the model across multiple GPUs or TPUs spreads the processing load, reducing delays.
Choosing the Right Hardware for Faster Inference
| Hardware | Best For | Speed Considerations | Cost |
| GPU (NVIDIA A100, H100) | Large-scale LLM hosting | Fastest for high-throughput models | High |
| TPU (Google Cloud TPUv4) | Optimized for Transformer-based models | Slightly faster than GPUs for specific workloads | Expensive |
| CPU (Intel Xeon, AMD EPYC) | Small-scale chatbots, low-cost deployment | Much slower than GPUs/TPUs | Low |
If your chatbot is API-based, cloud GPU instances like AWS Inferential or Google TPU can speed up inference without requiring your own hardware. If you’re self-hosting, NVIDIA GPUs are the best bet for real-time LLM performance.
Network & API Latency Issues
Chatbots that rely on API calls introduce network delays, especially when requests travel between multiple servers before reaching an LLM. The choice between cloud-based APIs vs. self-hosted models plays a big role in response time.
Cloud-Based API Chatbots: Easier but Slower
- Services like OpenAI, Anthropic, and Cohere allow easy integration but add latency because every user query needs to travel across the internet before the model processes it.
- Average latency for cloud-based chatbots: 500ms – 3s per query (varies by provider & model).
Self-Hosted LLMs: Faster but Requires Setup
- Running the model on your own server avoids API request delays, making chatbots faster.
- Needs good infrastructure (GPU/TPU clusters, optimized memory allocation).
Reducing API Latency with Load Balancing & Batching
- Load balancing ensures requests are evenly distributed across multiple nodes, preventing server overload.
- Request batching groups multiple user queries into a single processing cycle, reducing individual wait times.
If you’re running a high-volume chatbot, moving to a self-hosted, optimized model can significantly reduce response time.
Techniques to Reduce Latency in LLM-Based Chatbots
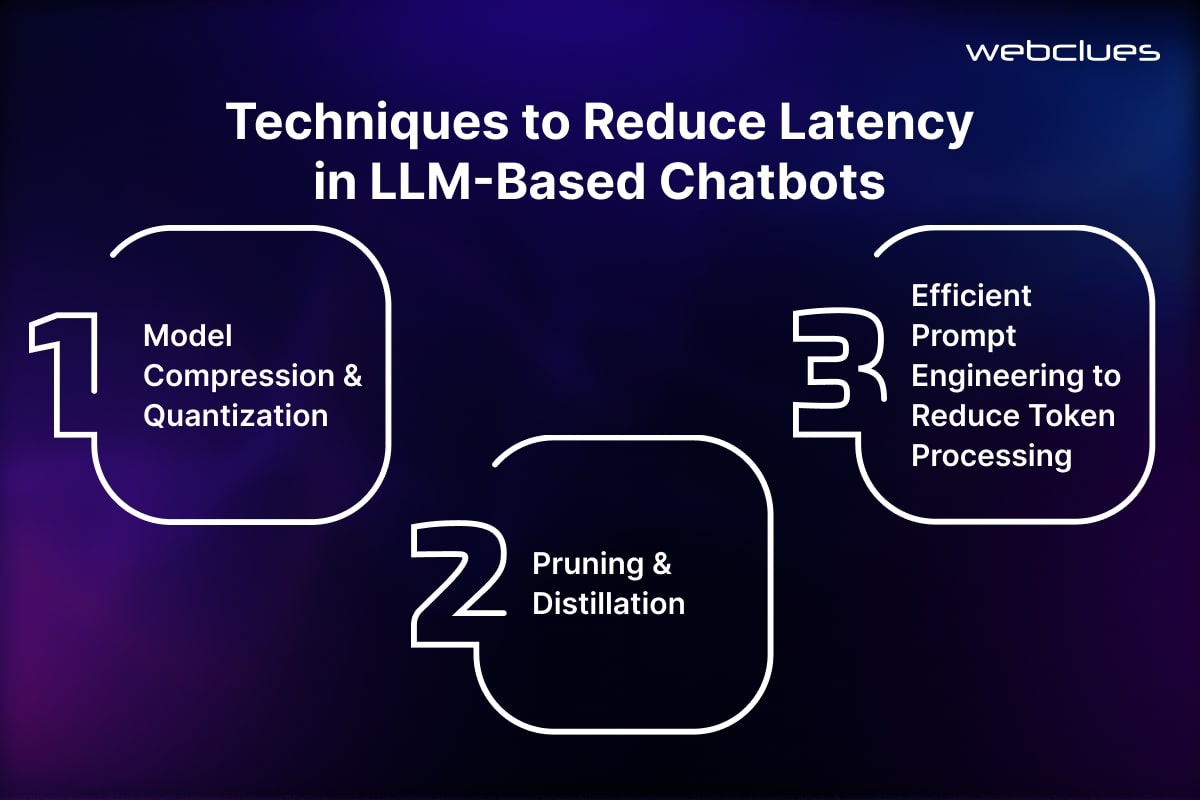
Reducing latency in chatbots isn’t just about faster hardware—it’s also about optimizing the model and its interactions. Large Language Models (LLMs) process a lot of data, but there are ways to make them run faster without losing accuracy.
Here are three key techniques that help reduce processing time while keeping chatbot responses sharp.
Model Compression & Quantization
LLMs are built with millions or even billions of parameters, and running them efficiently can be expensive. Quantization and model compression are two effective ways to speed up inference without losing too much accuracy.
Quantization: Making Models Lighter for Faster Processing
Quantization reduces the precision of model weights from FP32 (32-bit floating point) to INT8 (8-bit integers). This makes calculations lighter and faster, cutting down inference time significantly.
There are two main types of quantization:
- Post-Training Quantization (PTQ): Converts the model’s weights after training without retraining.
- Quantization-Aware Training (QAT): Adjusts the model during training to minimize accuracy loss.
Here’s how you can apply INT8 quantization to a model using PyTorch:

This simple change can reduce inference time by up to 50% without noticeable accuracy loss.
Optimizing for Hardware: TensorRT & ONNX
For NVIDIA GPUs, TensorRT and ONNX Runtime can further improve speed:
- TensorRT optimizes LLM execution on NVIDIA GPUs.
- ONNX Runtime allows cross-platform model optimization and deployment.
Using ONNX for faster inference:

These optimizations reduce processing delays and cut down GPU memory usage, making chatbots run faster with the same hardware.
Pruning & Distillation
Even within a large model, not all parameters are necessary for every task. Pruning and distillation are two methods that help reduce model size while keeping performance intact.
Pruning: Removing Unnecessary Weights
Pruning eliminates less important parameters from the model, reducing complexity and inference time. Structured pruning targets specific layers, while unstructured pruning removes individual weights.
Example:
- Removing attention heads that contribute less to chatbot performance.
- Cutting down redundant neuron
Distillation: Training a Smaller Model from a Large One
Instead of running a huge model, you can train a smaller model to mimic its behavior using knowledge distillation.
A well-known example is DistilBERT, which achieves 60% faster inference than BERT while keeping 95% of its accuracy.
Here’s how knowledge distillation works:
- A teacher model (large LLM) generates soft labels for training data.
- A student model (smaller LLM) learns from these outputs instead of raw data.
This method reduces latency drastically, making chatbot responses faster without retraining a large model from scratch.
Efficient Prompt Engineering to Reduce Token Processing
LLMs generate responses token by token, and longer prompts take longer to process. By optimizing prompts, you can cut down processing time while keeping responses accurate.
Why Shorter Prompts Work Better
- Less token usage = faster response time.
- More direct prompts get to the point without extra processing.
Here’s an example:
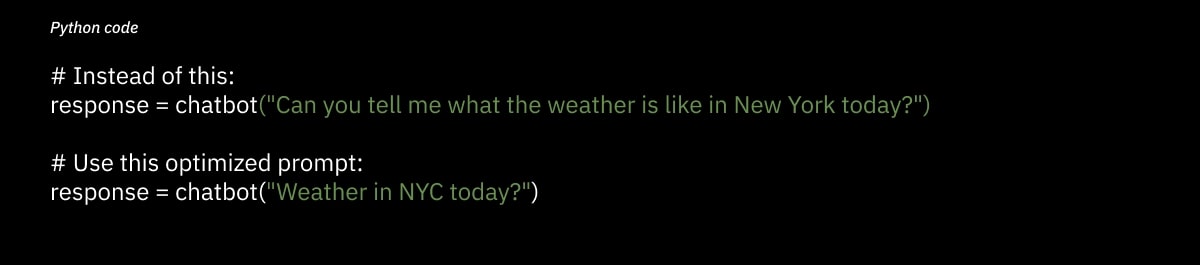
Both prompts ask the same question, but the second one reduces token count significantly. In a high-volume chatbot, small changes like this add up, cutting down inference time for every request.
Using Templates for Faster Response Generation
If your chatbot frequently handles similar queries, pre-designed prompt templates can reduce processing overhead.
Example:
- Instead of dynamically constructing full-length prompts, use:

This ensures efficient token usage without compromising response quality.
Putting It All Together
Latency optimization is about finding the right balance between model efficiency, hardware, and structured inputs. By applying quantization, pruning, distillation, and prompt engineering, chatbot responses can be made faster and smoother.
Factors Affecting Response Accuracy in LLM-Based Chatbots
Speed is important, but accuracy is what makes a chatbot reliable. If a chatbot hallucinates, gives incomplete answers, or misinterprets user intent, it quickly becomes frustrating to use. Developers often struggle to find the right balance between speed and correctness.
Here are some key reasons why chatbot responses may be inaccurate and what can be done to fix
Model Hallucinations & Incorrect Responses
LLMs predict the next word based on probabilities from their training data. When they don’t have the right information, they fill in the gaps—often with made-up or misleading answers. This is called hallucination, and it’s a major issue in AI chatbots.
Why Hallucinations Happen
- Limited training data – LLMs can only respond based on what they’ve seen before.
- Lack of real-time knowledge – Most models don’t access the internet or external sources.
- Overconfidence in low-confidence responses – Even when unsure, LLMs generate responses instead of saying, “I don’t know.”
Ways to Reduce Hallucinations
Fine-Tuning Models with Better Data
- Training on domain-specific datasets makes chatbots more reliable in niche areas.
- Example: A chatbot for medical advice should be trained on peer-reviewed medical papers, not just general internet data.
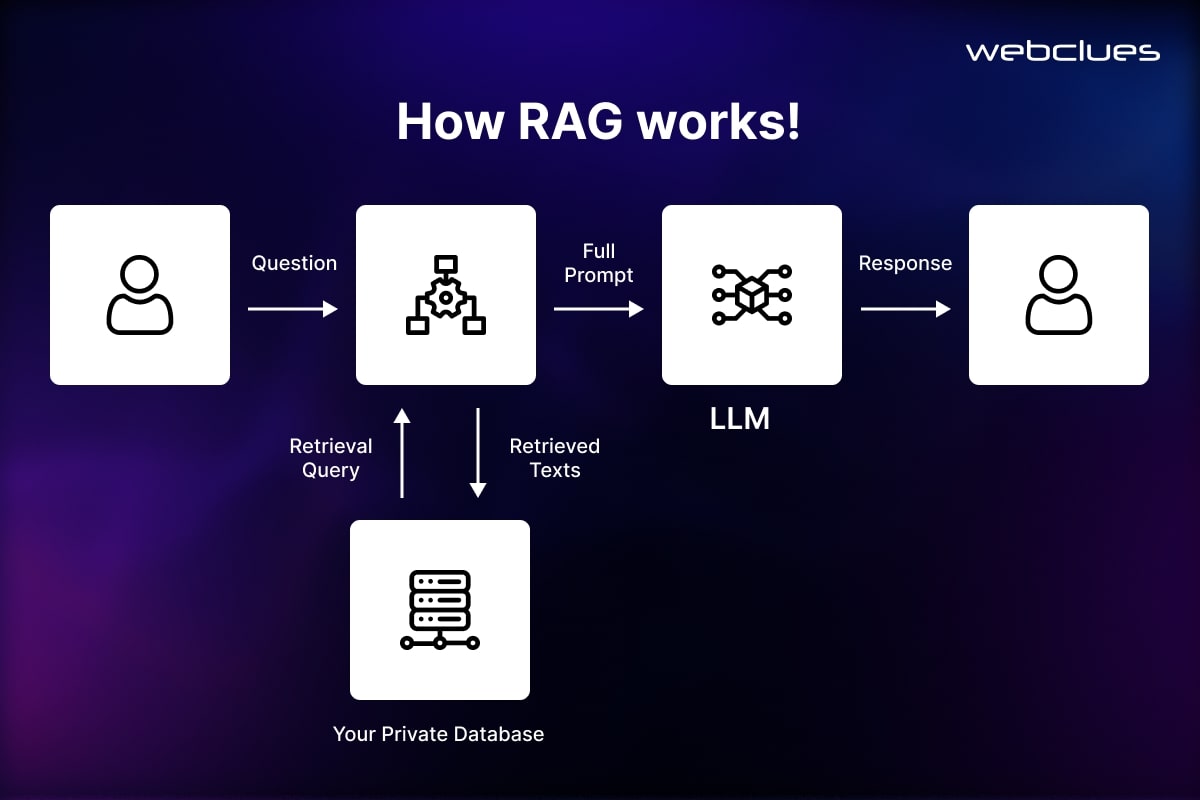
Using External Knowledge Bases (Retrieval-Augmented Generation - RAG)
- Instead of only relying on LLM memory, fetch real-time data from trusted sources.
- Example: A chatbot answering legal questions should pull from official legal databases.
- RAG helps chatbots cross-check their own responses before answering.
Context Length & Memory Constraints
Chatbots work well in short conversations, but long interactions can make them lose context. Since most LLMs only process a limited number of tokens at a time, they may forget earlier parts of the conversation.
Common Issues with Long Conversations
- Context loss – The chatbot forgets earlier messages in a chat.
- Repetitive responses – Since it can’t recall past interactions, it might repeat itself.
- Increased latency – Passing too much data slows down responses.
Solutions to Maintain Context in Long Conversations
Sliding Window Attention
- Instead of processing the full chat history every time, the chatbot focuses on the most relevant past messages.
- This keeps responses relevant without slowing down inference.
Memory-Augmented Transformers
- Some chatbots store past conversations in a short-term memory buffer, so they don’t have to reprocess old data every time.
- This method reduces token usage while keeping interactions meaningful.
Example:
Instead of storing the entire conversation history, store key summary points:
- “User is looking for laptop recommendations.”
- “User prefers gaming laptops under $1000.”
- “User already checked Dell and Lenovo options.”
Now, the chatbot remembers the user’s needs without storing unnecessary details.
Handling Ambiguous User Queries
Users often ask vague or unclear questions, making it hard for chatbots to figure out what they actually need. Instead of guessing, LLMs should retrieve relevant context before answering.
How to Improve Query Understanding?
Using Embeddings & Semantic Search
- Instead of just matching keywords, embeddings help find meaning in a query.
- This allows chatbots to understand user intent, even if phrased differently.
Example: Using Embeddings for Better Query Handling

Now, instead of searching for exact words, the chatbot can compare meaning against a database of known topics and return the most relevant response.
Multi-Turn Disambiguation
If the chatbot isn’t sure about a user’s request, it should ask clarifying questions instead of making random guesses.
Example:
User: “Tell me about payments.”
Chatbot: “Are you asking about payment methods or transaction issues?”
This avoids incorrect responses and guides the user to the right answer.
Why Accuracy Matters
A chatbot that responds quickly but gives wrong answers isn’t useful. The goal is to make chatbots both fast and reliable by:
- Fine-tuning models with relevant data.
- Using retrieval-based methods (RAG) instead of pure generative responses.
- Keeping context while avoiding unnecessary processing.
- Handling vague questions properly instead of guessing.
Strategies to Improve Chatbot Response Accuracy
Even with a well-optimized chatbot, accuracy issues can still show up. Large Language Models (LLMs) are great at generating responses, but they don’t always retrieve the right information or understand user intent perfectly.
Here are three practical strategies to make chatbot responses more reliable and relevant.
Using Retrieval-Augmented Generation (RAG) Instead of Fine-Tuning
LLMs only know what they were trained on—which means they can’t pull in real-time data or update knowledge dynamically. Fine-tuning helps adapt models for specific topics, but it’s expensive and needs frequent retraining.
A better approach? Retrieval-Augmented Generation (RAG).
How RAG Improves Chatbot Responses
- Instead of relying only on an LLM’s training data, RAG fetches relevant facts from an external database before generating a response.
- It’s faster and cheaper than retraining an entire model.
How to Use FAISS for Fast Knowledge Retrieval
FAISS (Facebook AI Similarity Search) helps store and retrieve relevant embeddings efficiently.
Here’s how to build an embedding index using FAISS:

Now, when a chatbot gets a new query, it can:
- Convert the query into an embedding.
- Search for the closest match in the FAISS index.
- Retrieve the most relevant knowledge before generating a response.
This method keeps responses accurate and avoids hallucination by grounding answers in real data.
Reinforcement Learning from Human Feedback (RLHF)
Even well-trained models make mistakes—but they can learn from human feedback over time. Reinforcement Learning from Human Feedback (RLHF) helps chatbots improve their accuracy by adjusting based on real-world interactions.
How RLHF Works
- Users rate chatbot responses or select the best-generated answers.
- A reward model trains the chatbot to favor high-quality responses.
- The chatbot learns which answers are useful and avoids repeating mistakes.
Training a Chatbot with RLHF

Over time, RLHF improves response quality by prioritizing answers that users find most helpful.
Where is RLHF useful?
- Customer service bots that need constant refinement.
- Legal, medical, and financial chatbots, where accuracy is critical.
- AI assistants that handle complex, multi-turn conversations.
Combining LLMs with Rule-Based Systems for Accuracy Control
LLMs are great at open-ended conversations, but for structured queries, a rule-based system is often better. A hybrid approach combines both, letting LLMs handle free-form responses while rules manage specific tasks.
When to Use Rule-Based Responses?
- Simple, structured queries (e.g., checking account balances, tracking orders).
- High-risk queries (e.g., financial transactions, security checks).
- Compliance-sensitive industries (e.g., banking, healthcare).
Example: Hybrid AI for a Banking Chatbot

In this setup:
- The rule-based function handles account balance checks directly.
- The LLM processes open-ended questions like “How can I save more money?”.
This method keeps chatbot responses accurate, avoids unnecessary processing, and prevents hallucinated answers in critical areas.
Making Chatbots Smarter
Optimizing chatbot accuracy isn’t just about fine-tuning—it’s about using the right strategies for different situations:
- RAG for real-time knowledge retrieval instead of retraining models.
- RLHF to let chatbots learn from user feedback and improve over time.
- Hybrid AI systems to handle structured tasks with rules while allowing LLMs to manage open-ended conversations.
Deployment Strategies for Optimized Chatbots
Once a chatbot is optimized for speed and accuracy, the next step is deploying it efficiently. The way an LLM-based chatbot is hosted and scaled impacts response time, cost, and reliability.
Here’s a look at how to choose the right inference engine and balance cost with performance when deploying AI chatbots.
Choosing the Right Inference Engine for Production
Running an LLM efficiently requires optimized inference engines that reduce latency and processing overhead. Not all inference engines are the same, and choosing the right one depends on your hardware and use case.
Comparing Popular Inference Engines
| Inference Engine | Best For | Key Benefit |
| TensorRT (NVIDIA) | High-speed GPU inference | Optimized for NVIDIA GPUs, great for low-latency tasks |
| vLLM | High-throughput LLMs | Uses continuous batching to handle large workloads efficiently |
| ONNX Runtime | Cross-platform deployment | Runs on CPU, GPU, and mobile devices |
Using TensorRT for Faster LLM Inference
TensorRT is an NVIDIA-backed framework that accelerates deep learning models for faster GPU processing. It works well for real-time chatbots that need low-latency responses.

By optimizing LLM execution on GPUs, TensorRT reduces inference time and lowers memory usage.
Scaling Chatbots with Kubernetes
For chatbots handling high traffic, auto-scaling ensures that resources scale up or down based on demand. Kubernetes (K8s) is commonly used to deploy, manage, and scale LLM-based chatbots across multiple nodes.
Example: Deploying an AI chatbot with Kubernetes

With auto-scaling, Kubernetes adjusts the number of active chatbot instances based on real-time traffic, reducing wasted resources during low-traffic periods.
Cost vs. Performance Trade-offs
The choice between cloud inference and on-prem hosting depends on budget, traffic volume, and required response speed.
Cloud vs. On-Prem: Which One Works Best?
| Deployment Type | Pros | Cons | Best Use Case |
| Cloud Inference (AWS, GCP, Azure) | No infrastructure setup, easy scaling | Higher costs at scale | Chatbots with unpredictable traffic |
| On-Prem Hosting (Self-hosted LLMs on GPUs) | Lower cost per inference at scale | Requires dedicated hardware | High-traffic chatbots with stable usage |
When to Use Cloud-Based Inference?
- If chatbot traffic fluctuates (e.g., e-commerce or seasonal use cases).
- If hardware investment isn’t an option.
- If quick deployment is a priority.
When to Host Models On-Prem?
- If the chatbot runs at scale, making GPU cloud costs too high.
- If data privacy is a concern (banks, healthcare, enterprise apps).
- If the chatbot needs consistent, high-speed responses with low ongoing costs.
Setting Up for Long-Term Efficiency
Choosing the right inference engine and deployment strategy makes a big difference in chatbot speed, cost, and scalability.
- TensorRT, vLLM, and ONNX Runtime offer different optimization paths depending on hardware.
- Kubernetes and auto-scaling help handle peak loads efficiently.
- Cloud vs. on-prem should be decided based on budget, traffic, and performance needs.
Future of LLM-Based Chatbot Optimization
LLM-based chatbots are getting faster, smarter, and more efficient, but there’s still room for improvement. The next phase of chatbot optimization focuses on reducing latency even further and making models adapt in real time without constant retraining.
Low-Latency On-Device LLM Inference
Most chatbots today run on cloud servers or dedicated GPU clusters, but that comes with network latency and high infrastructure costs. A new shift is happening—bringing LLM inference directly to devices like smartphones, laptops, and edge AI hardware.
Why On-Device Inference Matters
- Faster responses – No need to wait for API requests to go back and forth.
- Lower costs – Less reliance on expensive cloud GPUs.
- Better privacy – User data stays on the device instead of being sent to external servers.
How It Works
- Quantization & model distillation make large models small enough to run on mobile chips.
- Frameworks like ONNX and TensorFlow Lite optimize inference for low-power devices.
- Dedicated AI hardware (like Apple’s Neural Engine or Qualcomm’s AI cores) helps process chatbot responses locally.
Using Federated Learning for Real-Time Chatbot Adaptation
Most LLMs require centralized training, meaning any updates or improvements need a full retraining cycle. Federated learning changes this by allowing chatbots to learn from user interactions in real time—without sending raw data to a central server.
How Federated Learning Works
- Instead of collecting all user data in one place, each chatbot instance learns locally.
- The local updates are sent as encrypted model improvements (not raw data).
- A central system aggregates these improvements and updates the main model.
Why This is a Game Changer
- Chatbots improve without retraining from scratch.
- Users get personalized responses while keeping their data private.
- Reduces cloud storage and bandwidth costs.
What’s Next for AI Chatbots?
The future of chatbot optimization is about cutting down latency and improving accuracy without massive infrastructure costs.
- On-device inference will make chatbots faster and more private.
- Federated learning will help chatbots learn in real time without central data collection.
As these technologies improve, chatbots will become even more efficient, delivering real-time, reliable responses without needing expensive cloud servers.
Why Choose WebClues Infotech for AI Chatbot Development?
Building an AI chatbot that is fast, accurate, and scalable takes more than just plugging in an LLM. It requires careful optimization, the right infrastructure, and continuous improvements to keep it running smoothly. That’s where WebClues Infotech comes in.
Industry-Leading Expertise in AI Chatbots
Our team has worked on LLM optimization, chatbot infrastructure, and real-time AI applications across industries. Whether it's reducing latency, improving response accuracy, or deploying AI models efficiently, we know what works.
Custom AI Model Tuning & Deployment
Every chatbot is different. We fine-tune models for specific industries, languages, and business needs, ensuring they deliver reliable and context-aware responses. From model quantization to hybrid AI approaches, we set up chatbots for real-world performance.
Scalable, High-Performance AI Chatbot Solutions
We build chatbots that can handle real-world traffic without slowing down.
- Optimized inference engines (TensorRT, vLLM, ONNX).
- Auto-scaling infrastructure (Kubernetes, cloud-based or on-prem hosting).
- Hybrid AI architectures that mix LLMs with rule-based systems for better accuracy.
Want a chatbot that runs fast and delivers the right answers?
Schedule a Free AI Consultation with WebClues Infotech Today!
Final Takeaway
Optimizing an LLM-based chatbot isn’t just about making it work—it’s about making it fast, accurate, and scalable. A slow chatbot frustrates users, and an inaccurate one creates confusion instead of solving problems.
To get the best performance, developers need to focus on:
- Reducing latency with model quantization, pruning, and efficient inference engines.
- Improving accuracy by combining retrieval-based methods, fine-tuning, and hybrid AI systems.
- Choosing the right deployment strategy—whether it’s cloud-based, on-prem, or on-device inference.
Building a chatbot that delivers fast and reliable responses takes the right mix of AI optimization and infrastructure setup. If you’re looking to develop an AI chatbot that runs efficiently at scale, we can help.
Want to build a fast, accurate AI chatbot?
Contact WebClues Infotech today!
Post Author

Nikhil Patel
Nikhil Patel, a visionary Director at WebClues Infotech, specializes in leveraging emerging tech, particularly Generative AI, to improve corporate communications. Through his insightful blog posts, he empowers businesses to succeed digitally.


Build Your Agile Team
Hire Skilled Developer From Us
Build low-latency AI chatbots that respond with enhanced accuracy with WebClues
High latency and inaccurate responses don’t have to slow your chatbot down. WebClues helps businesses deploy fast, reliable AI chatbots using advanced optimization techniques. From latency reduction to hybrid AI approaches, we handle it all.
Connect Now!Our Recent Blogs
Sharing knowledge helps us grow, stay motivated and stay on-track with frontier technological and design concepts. Developers and business innovators, customers and employees - our events are all about you.